10个让网络爬虫顺利索引站点的方法
爬虫从页面抓取内容索引站点并使用这些页面上的链接来查找更多页面,这样便可以在互联网上找到更多内容。这里面涉及几个技术点:URL 来源:爬虫必须从某个地方开始。通常会创建一个列表(外链),列出他们通过页面找到的所有 URL;另外一个机制就是通过用户或具有页面列表的各种系统创建的站点地图来查找更多 URL。
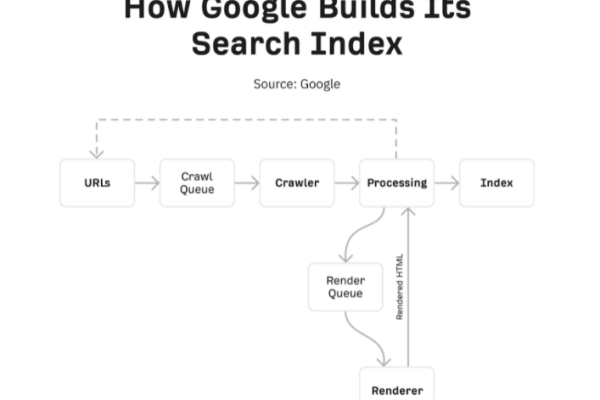
爬虫从页面抓取内容索引站点并使用这些页面上的链接来查找更多页面,这样便可以在互联网上找到更多内容。这里面涉及几个技术点:URL 来源:爬虫必须从某个地方开始。通常会创建一个列表(外链),列出他们通过页面找到的所有 URL;另外一个机制就是通过用户或具有页面列表的各种系统创建的站点地图来查找更多 URL。

一、 Beautiful Soup 安装 Beautiful Soup 提供一些简单的、Python 式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据

XPath(XML Path Language),即 XML 路径语⾔,它是⼀⻔在 XML ⽂档中查找信息的语⾔。最初是⽤来搜寻 XML ⽂档的,但同样适⽤于 HTML ⽂档的搜索,所以在做爬⾍时完全

Requests 库是用来发标准 HTTP 请求的包,将请求背后的复杂性抽象成一个漂亮,简单的 API,以便可以专注于与服务交互和在应用程序中使用数据。 一、Requests 安装 安装&n