
文章标题写作方式梳理
做 SEO 的朋友都知道文章标题的重要性,尤其是那种让人眼前一亮的标题,对文章点击率提升有很大的帮助。之前的文章中也介绍了一些文章标题写作的方式,那这篇文章就先简单梳理下之前提及的方式,最后再介绍一种 […]
做 SEO 的朋友都知道文章标题的重要性,尤其是那种让人眼前一亮的标题,对文章点击率提升有很大的帮助。之前的文章中也介绍了一些文章标题写作的方式,那这篇文章就先简单梳理下之前提及的方式,最后再介绍一种 […]
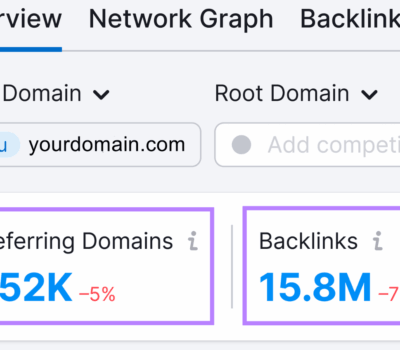
昨天聊了衡量 SEO 成效的前 5 个指标,那今天接着昨天的话题,继续把剩下的 5 个指标说说。 第六个要说的就是网站权重(Website Authority)。顾名思义,这个 SEO 指标在某种程度
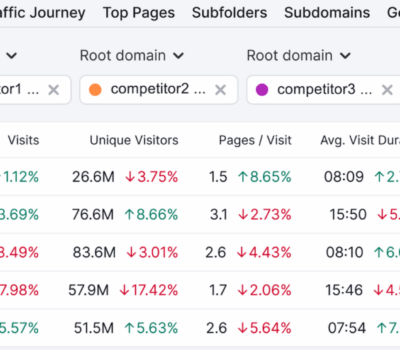
在我眼里,SEO 是马拉松(类似于人生),前期需要付出很长时间的努力,且有可能根本看不到任何回报。所以能不能坚持、能不能有延时满足感就显得特别重要。 那今天就分享一点如何衡量 SEO 成效的方法,系统
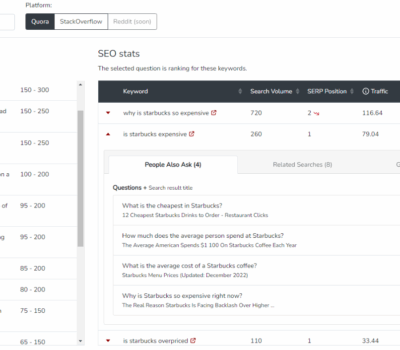
昨天的文章《关注关键词的衍生话题》中,我说可以去重点关注关键词话题。但因为篇幅的原因,并没有详细说明获取关键词话题的方法,那今天这篇文章就将这个点补充一下。 第一个常见的方法就是谷歌搜索结果页的“Pe
白天一直在帮朋友修两个网站(加载速度上不去),整整一天时间都在对着电脑,人都快傻掉了。那晚上这篇文章就聊点轻松的话题,讲讲重点关注由关键词衍生而来的话题的缘由,明天有可能的话再聊聊从哪些渠道去关注这些
晚上交流群里聊天,有新入行的朋友在反馈 NICHE 难定位的问题。确实,对于一位刚入行,没什么跨境流量运营经验的新人来说,突然一下子要选出一个适合自己的、且竞争程度并不是很高的 NICHE 市场,绝非
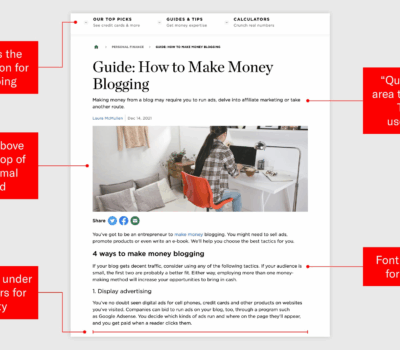
之前写过一篇文章,简单讲了商品评论型文章(俗称带货文)如何布局的问题。那今天这篇就聊聊博客文章应该如何布局。提前说明一点,文章中用到的两张图片源于网络,并非我制作的,只是一直收藏在手机相册,现在实在没
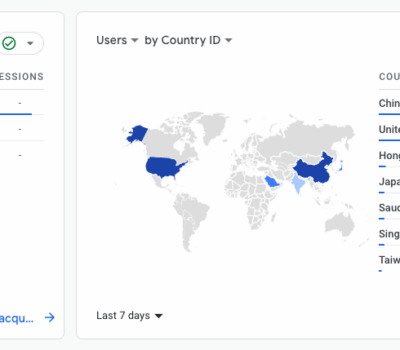
在正文开始之前,我想聊聊推广方式选择的问题。起因是今天有跟做投放的朋友聊过这个话题,觉得有点感触,想记录下来。 其实无论是广告投放也好,SEO 也罢,都只不过是流量获取方式的一种,本质上没什么好坏之分

端午假期第一天,什么任务都没安排,在陪家人。 晚上浏览 SEO 领域相关信息的时候,发现了 Ahrefs 一篇很有意思的文章,讲的是 SEO 过程中的 13 种关键词类型。要比我了解到的 4 种类型(
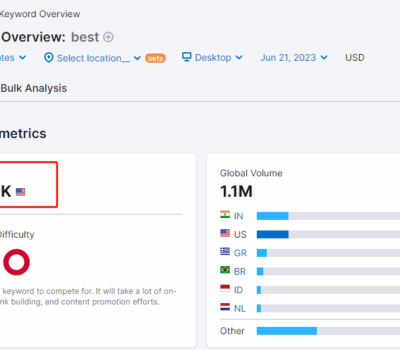
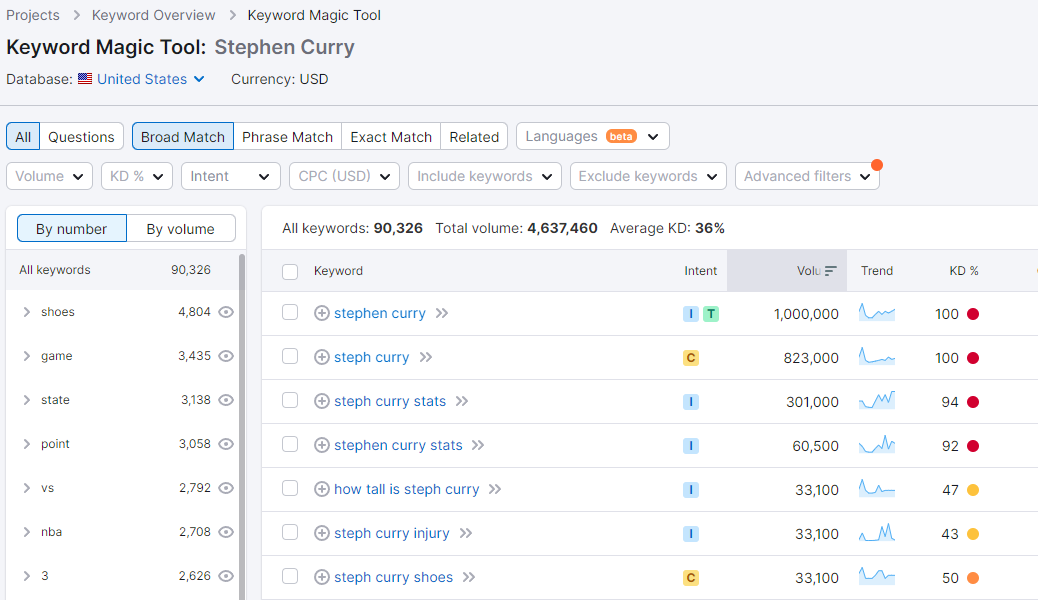
之前的文章里,分享了两种找低竞争关键词的方法。其一是通过红海词的搜索结果页,定位比较弱的竞争对手,来搜寻蓝海长尾词;其二是利用亚马逊的产品类目,来寻找那些低竞争的领域。 诚然,这两种方法都比较耗精力,
本来今天想输出一份如何调研竞争对手的方案,但是内容大纲列出来,真的太长了,半个小时内绝对写不完,干脆作罢,后续专门抽一块周末时间来做这件事。那今天就聊聊一个在沟通群里,有朋友问到的信息,B 端外贸询盘
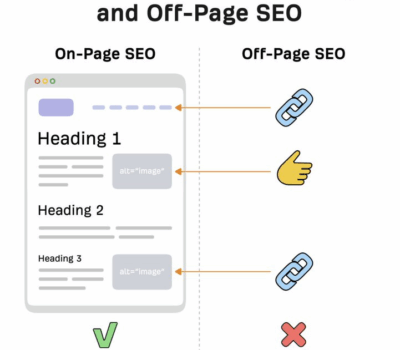
今天聊点轻松的技术性话题,On-page SEO 与 Off-page SEO 之间的区别比较。我发现比较多朋友不清楚这块的逻辑,所以特地写篇文章简单说说。 其实区别很简单,只要记住一句话就行。对于你
昨天内部交流群里,有朋友问到“营销站怎么启动”这块的问题。那我就从我有限的经验里,聊聊我对联盟营销站怎么启动这块的看法。可能观点有失偏颇,欢迎交流讨论。 我是 18 年底从程序员转行到联盟营销站运营,
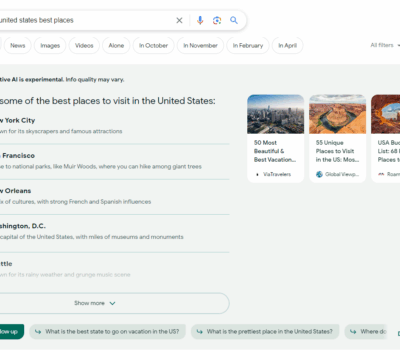
使用谷歌的 SGE(Search Generative Experience)已经有一段时间了,且最近也看了不少官方出的资料。所以今天想聊聊,我对此的一点浅显看法,欢迎交流。 做 SEO 的朋友都知道
文章开始之前,先说两个事情。 其一,我昨天晚上花了点时间,将知识星球内的帖子,分门别类的整理出来了,并做了一个独立站从零到一的新手指南。我想新手朋友照个这份文档去执行,做出属于自己的第一个独立站并不是
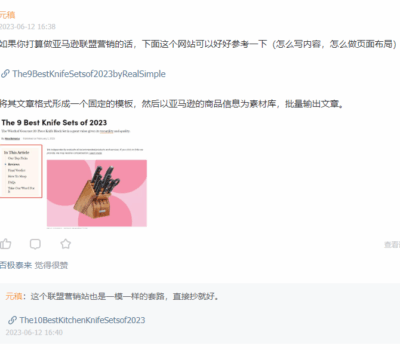
之前的文章,我详细介绍了如何通过亚马逊类目列表,发掘蓝海关键词的方法。这种大力出奇迹的方法,也确实帮助一些朋友找到了,心仪的蓝海关键词。且我下一阶段也打算开发一款专门的程序,去批量发掘蓝海关键词,来为
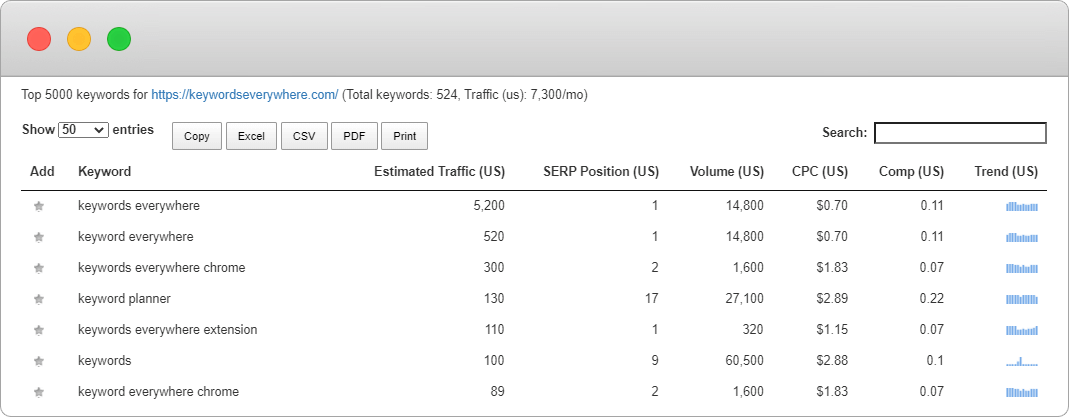
上个月发了篇文章,讲的是做低竞争的关键词。那篇文章里,我只是说了为什么要去做低竞争关键词,顺带着分享了一个案例,但是没有详细说如何去做低竞争的关键词。 那今天这篇文章就聊聊低竞争的关键词如何做,以及我
最近比较多朋友在后台私信我,怎么去选择 NICHE,或者咨询什么样的 NICHE 比较赚钱。其实说实话,我哪知道,赚钱的 NICHE 都是不断测试出来的,且基本没几个人愿意将正在做的 NICHE 分享
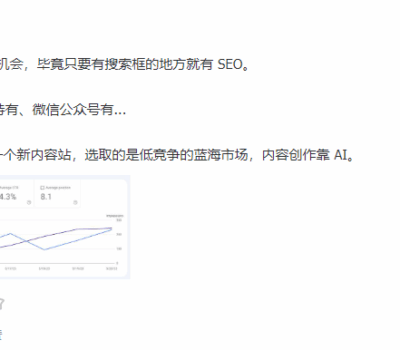
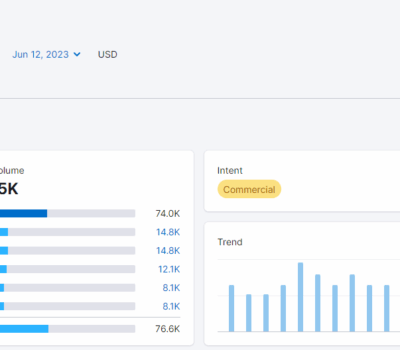
下午在知识星球更新了一张照片,显示的是我上周新建的一个站点的后台数据。实话说,这个数据有点出乎我的意料,也根本没料想到收录、排名会这么快,短短几天的时间便开始有密集的访客进来。 做这个 NICHE 市
无论是电商项目还是独立站项目,我认为第一步都是定位自己的竞争对手,这点对于一个项目是否能获得成功十分关键。通过锚定你的竞争对手,你可以学习他的选品方法、页面装修与布局、关键词策略等等,了解清楚这些基础
知道时颖有独立站是在去年,跟朋友聊天时得知,之前一直以为他们只做平台。作为大泉州地区在跨境电商领域做的比较大的一家公司,我一直在关注着他们家独立站的状态,那今天咱就聊聊时颖的独立站。 由于篇幅比较长,
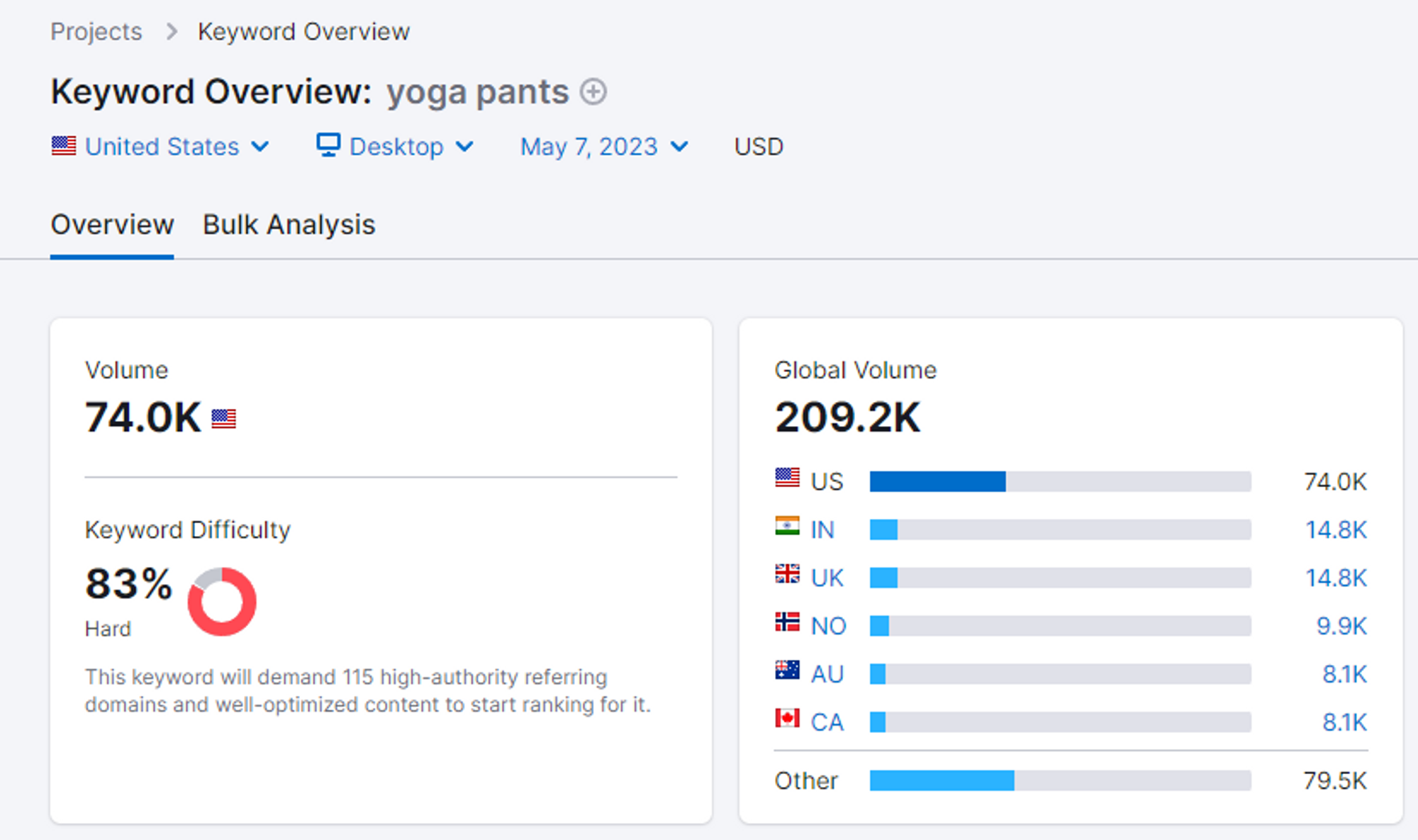
之前我写的文章里,一直有费比较重的笔墨在强调谷歌 SEO 流量运营的优点。但你要知道其实做谷歌 SEO 并不是那么简单,所以这篇文章就给那些想做 SEO 的朋友泼盆冷水,说说这个过程中的艰难曲折。 首

一台赚钱机器大致涉及到产品、流量、变现这三个方面,这篇文章就梳理下我知道的 8 种网站变现方式。万变不离其宗,所以后续我们在分析别人的项目时便可以往这些变现模式上套,好做到有的放矢,明白别人的项目到底
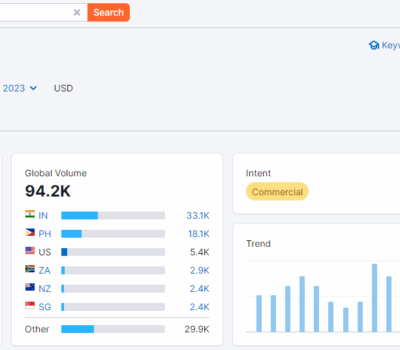
今天在进行关键词调研的时候发现一个很新颖有趣的网站,借着这篇文章就拆解下这个网站的运营模式。产品时怎么设计的?怎么做的冷启动流量?到底是如何变现的? 网站网址:https://gen.gifts/ 这